January 20, 2026
The Data Engineering Gap in Security


Nathan Koester
Staff Security Engineer @ Ironclad
Most security teams today are data teams, whether they realize it or not.
For years, the playbook was simple: collect everything, ship it to the SIEM, figure it out later. That worked until costs exploded, queries started taking hours, and teams realized they were locked into predatory multi-year contracts.
Then came the DIY era. Custom Python scripts, one-off RegEx parsers, custom built API integrations. It works, until the vendor’s API schema changes and you end up missing the last week of logs.
Now there's a third option: purpose-built security data pipelines that handle the ETL work so you don't have to become a data platform team.
How Teams Handle Security Data Today
Approach 1: "Just Send It to the SIEM"
If it logs, it ships. Centralized, out-of-the-box connectors, built-in correlation. Works great for small teams with 5-10 sources. Falls apart when SIEM vendor upcharges 150% in contract renewal or when the CISO asks "Are vulnerabilities trending down?". Then you realize there just are some things that the SIEM was never built for, but teams still do it.
Approach 2: The DIY Pipeline
Kafka, Glue, some homegrown Python and RegEx. Full “control”, scales to hundreds of sources, handles complex logic. Best for large orgs with existing data platform experience and a 6-12 month runway to build it.
The catch: you're committing to becoming a data platform team. Most security orgs underestimate the ongoing maintenance cost until they're living it.
Approach 3: Treating Security Data Like Product Data
Normalize, enrich, and route telemetry on your terms before it touches a SIEM or data lake. Native integrations handle API changes and schema drift. Pipeline health and observability. Export to multiple destinations simultaneously. Operational in days. No vendor lock-in.
Trade-off: less control over the underlying architecture. But if you don't have dedicated data engineering headcount, that's probably fine.
This is the approach I see more and more of my peers leaning towards given recent SIEM uncertainty.
Where Data Engineering Helps the Most
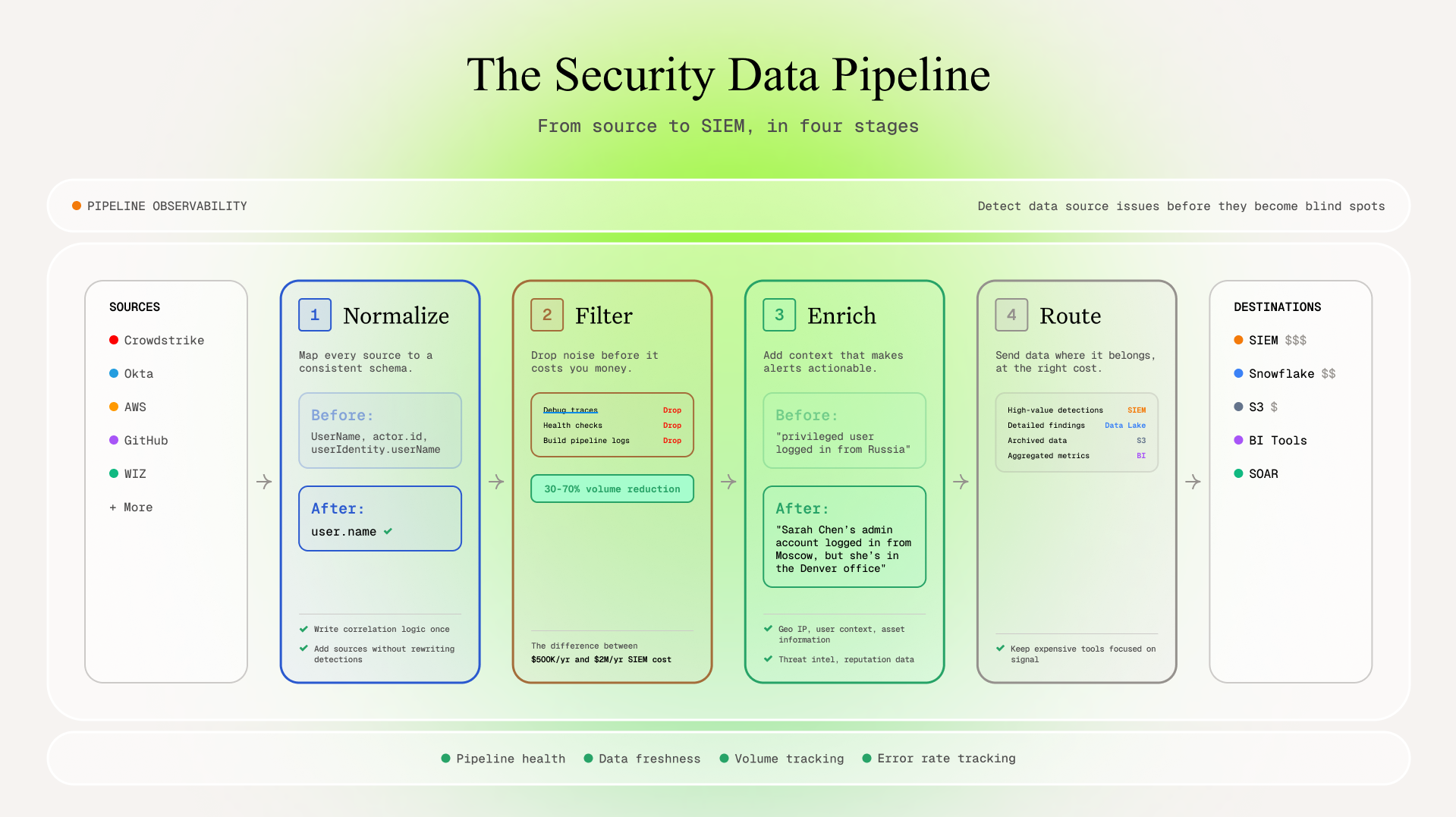
Normalization
Every tool speaks a different dialect. CrowdStrike timestamps look nothing like Okta's. One tool calls it user_name, another calls it userId, a third uses subject. Without consistent schemas, you end up writing the same correlation logic twelve different ways.
Real example: Migrating from Lacework to Threatstack required comparing asset coverage between platforms. Without normalized asset identifiers, it was miserable.
Filtering
The difference between paying $500K/year for a SIEM and $2M/year is often just better filtering upstream. Your SIEM doesn't need debug traces from your build pipeline.
Enrichment
"Privileged user logged in from Russia" vs. "Sarah Chen's admin account logged in from Moscow, but she's in the Denver office." The second alert is the one you can actually do something with.
Routing
High-value detections go to the SIEM. Detailed findings go to the data lakehouse. Archived data goes to S3. Aggregated metrics go to BI dashboards. Smart routing keeps your expensive tools focused on signal.
Observability and Pipeline Alerting
If your OpenAI Enterprise Audit Logs stopped flowing to your SIEM three days ago, does anyone notice? Broken pipelines don't just hurt detection but it makes incident response a MASSIVE pain. They could also distort every metric your leadership sees and bring everything else into question.
The Takeaway
You don't fix security data problems with another agent, dashboard, or scanning tool. You fix them with a pragmatic engineering discipline.
Solve it once, actually solve it, and the downstream effects compound. Detection engineers writing high fidelity detections instead of debugging parsers. Security logs and findings in the right place for the right use cases.High quality data you can actually trust when leadership asks hard questions etc.
Solving for security telemetry challenges isn't glamorous, but it makes everything downstream operate so much smoother. The great thing about it now, is that we no longer have to solve this all ourselves. Several solutions on the market can handle the heavy load while allowing security folks to focus on detection, prevention, hunting, and responding to threats.
I've looked at a few tools in this space. Monad is the one that's clicked most for me: handles the normalization, filtering, enrichment and routing without requiring me to staff up a data team. Worth a look if you're feeling this pain.
I'm Nathan Koester, a Staff Security Engineer at Ironclad with 7+ years in security engineering. I previously led cloud security at Veeva, securing AWS environments spanning 30K+ instances across 40 product teams and building an internal security datalake from scratch. Before that, I worked as a DoD contractor performing vulnerability assessments on Air Force systems and hardware reverse engineering for DARPA projects.
Related content
.png)
Darwin Salazar
|
July 16, 2026

.png)