February 24, 2026
Why Teams Are Decoupling Their SIEM from Their Data Pipeline

.jpeg)
Darwin Salazar
Head of Growth
TL;DR
SIEMs were built to search, alert, and detect threats. Somewhere along the way, they became the most expensive tool in your stack. The architecture and incentive mismatches are catching up with security teams, especially as AI tooling demands cleaner, more accessible data. Forward-thinking teams are separating the data layer from the SIEM to cut costs, eliminate vendor lock-in, and future-proof their stack. In this post, we cover what it looks like in practice.
How We Got Here
The core architecture of SIEMs was never designed to solve modern SOC problems. Think ingesting 5TB/day of logs from 40+ sources, varying schemas, inconsistent log quality, and low-fidelity atomic alerts. It's why forward-thinking teams at HSBC, Rippling, Brex, and countless others are decoupling their data pipeline from their SIEM. AI/ML tooling has put a magnifying glass on this problem. Models don't tolerate messy or incomplete data the way humans do.
We've built Monad to solve exactly this problem. The timing has always felt right, but now it feels more urgent than ever.
In this post, we'll break down why the SIEM-as-pipeline model is failing and what the alternative looks like.
Built to Search, Paid to Ingest
SIEMs were designed to be search engines with alerting capabilities. Somewhere along the way, vendors realized they could charge per gigabyte ingested, and log ingestion became a revenue driver rather than a customer success priority.
Think about what the SIEM actually does well: indexing logs, running queries, correlating events, creating historical baselines, and firing alerts.
Now think about what most SIEMs claim to do: collect data from N sources, normalize it into a consistent schema, route it to themselves, transform it and enrich it.
These are fundamentally different disciplines. The architectures don't overlap. And the incentive structures definitely don't overlap. SIEM vendors maintain hundreds of integrations across thousands of customers while simultaneously shipping AI SOC features, SOAR, UEBA, agentic threat hunting, risk scoring, and countless other capabilities. They're generalist platforms that thrive at search and alerting, not data engineering.
SIEM vendors make money when you ingest more data. They have zero incentive to help you route logs to cold storage at a fraction of the cost or send copies to your data lake for ML experiments.
Lock-in doesn't hurt on day one. It hurts on year three when your vendor raises prices 40% and you realize your entire detection library, your normalized schemas, your enrichment logic, and your historical data are all trapped in a proprietary format. Migration? Six months minimum.
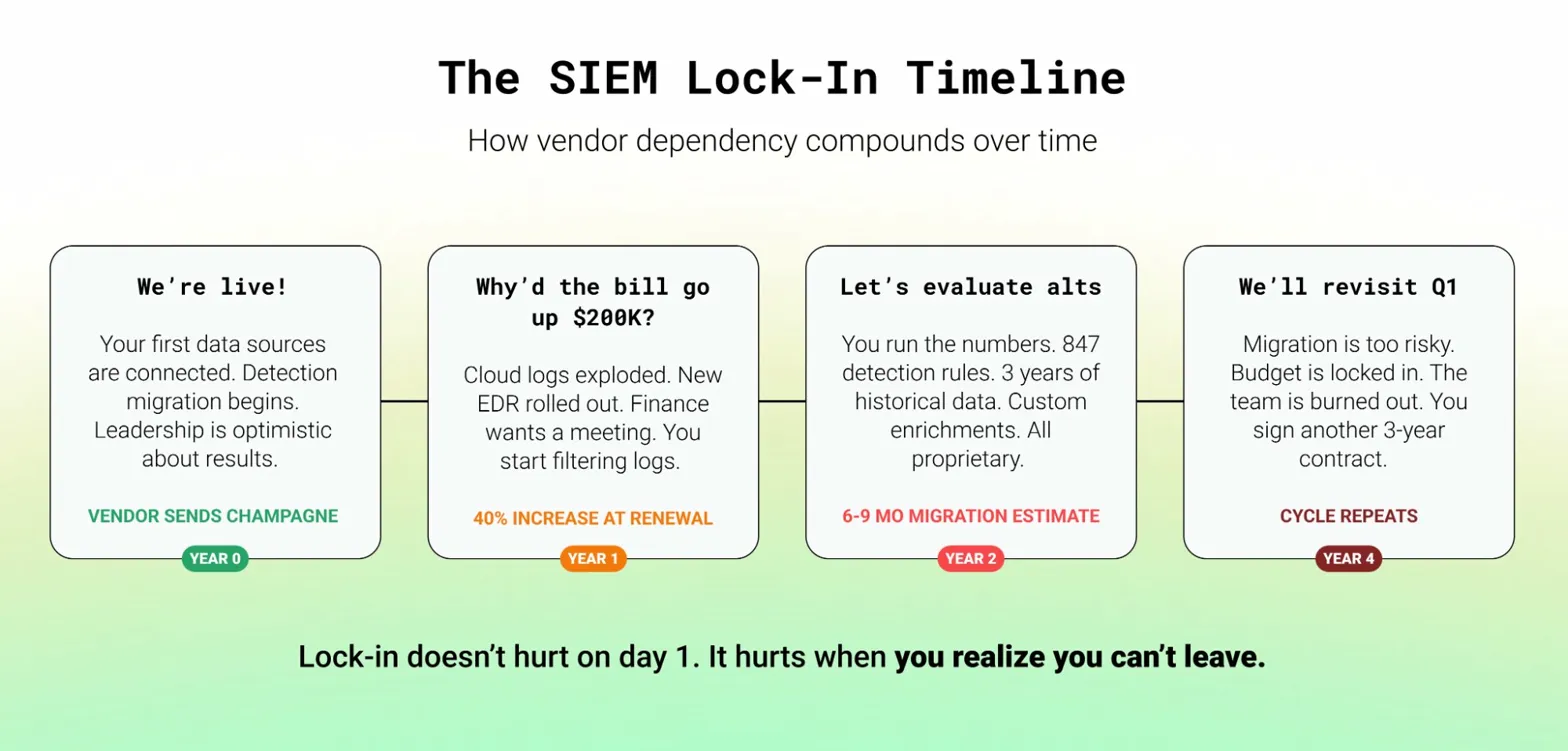
The Multi-Destination Era
Security data needs to live in more places than ever:
- SIEM for real-time detection and response
- Data lake + BI tools for threat hunting, dashboarding, and homegrown AI/ML
- Cold storage for compliance and incident response replay
- AI triage tools and analytics platforms that need access to the same telemetry
Now try to accomplish this with your SIEM as the central hub. Most SIEMs have little to no native support for routing data to external destinations. Splunk, for example, has no native integration to send data to Databricks or ClickHouse. This is the routing compatibility problem, and it's only gotten worse as security teams adopt more specialized tools and the enterprise sprawls into more SaaS and AI apps.
This is one of the core reasons we built Monad with 250+ integrations across sources and destinations. Your Okta logs shouldn't be locked into a single destination just because that's where your SIEM vendor decided they should go. With a dedicated pipeline, the same source data can flow to your SIEM for real-time detection, your Snowflake or Databricks instance for threat hunting, S3 for compliance retention, and your AI triage tool for automated analysis. One collection point, many destinations, zero duplication tax.
AI Doesn't Fix Bad Data
AI is changing how security teams operate, and every AI use case lives or dies on data quality and availability.
AI-powered SOC triage is the future. But right now, these tools are not ready for full unsupervised production use. Data availability and quality are the main culprits.
Talk to folks who have POC'd AI SOC vendors and you'll hear they demo beautifully, reduce MTTR tremendously, and the UI is slick. But dig into the actual triage output and reasoning and you may find the AI described a full attack chain: cmd.exe spawned PowerShell, which spawned certutil. But the actual data only had the certutil execution. The parent process fields were null. That's a model failure and a data failure. But only one of them is fixable at the pipeline layer.
When AI triage agents ingest unnormalized logs, heavily nested JSON with inconsistent field names, or events missing critical context, they hallucinate. They correlate events that shouldn't be correlated because timestamps are formatted differently across sources. They miss obvious conclusions because the enrichment data that would make it obvious was never joined.
AI SOCs are only as good as the data they can access:
- No HR data? Can't understand org structure.
- No asset inventory? Can't distinguish a server from a laptop.
- Missing identity logs? Flying blind on user behavior.
When your SIEM owns the pipeline, your data is normalized to their schema, optimized for their query engine, stored in their proprietary format. The organizations that stand to gain the most from AI in security are the ones with full control over their data layer.
This is where pipeline-level normalization and enrichment makes a real difference. When data is cleaned, schema-mapped, and enriched before it hits any downstream tool, whether that's your SIEM, your data lake, or your AI triage platform, every tool gets the same high-quality input. Monad handles this at the pipeline layer: normalizing fields across sources, enriching events with identity and asset context, and ensuring consistent schemas regardless of where the data ends up. The AI triage tool and the SIEM analyst are working from the same clean dataset.
Credit where it's due: Some AI SOC vendors like Prophet Security and Intezer aren't just throwing LLMs at messy data and hoping for the best. They're taking more deterministic, evidence-based approaches that surface data gaps rather than hallucinating over them. Pairing tools like these with a clean, well-structured data pipeline is where teams will see the most value.
What Decoupling Actually Looks Like
Decoupling means separating concerns, not building everything yourself.
Your data pipeline handles collection, parsing, normalization, enrichment, and routing. Source-agnostic. Destination-agnostic. Your SIEM and data lake receive clean, enriched data and do what they were built for: detection, investigation, and analysis.
Here's the practical architecture:
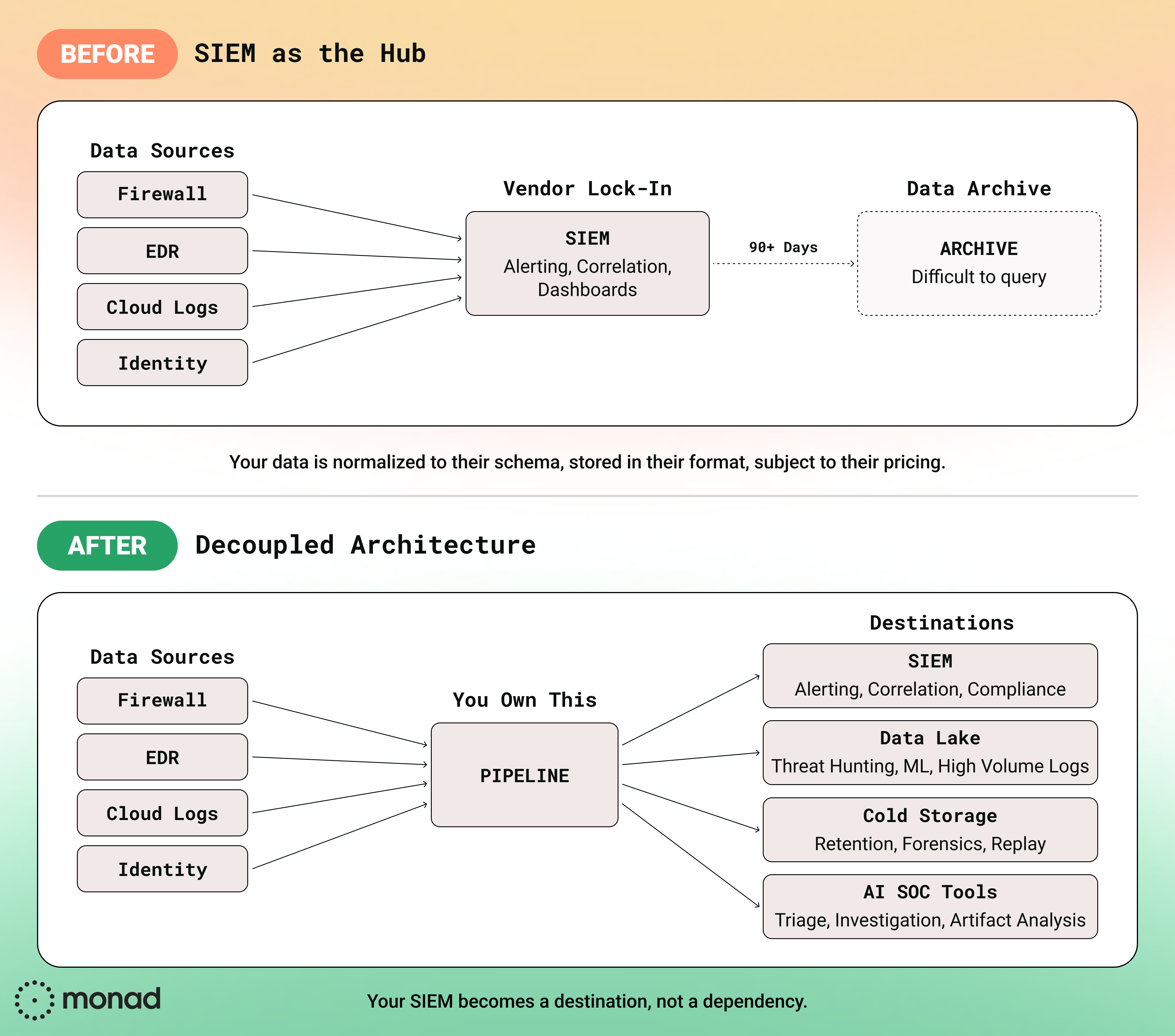
Purpose-built pipelines offer better filtering, routing flexibility, scalability, and observability, typically at a fraction of SIEM ingestion costs.
This also gives you real optionality:
- Migrate SIEMs? Your pipeline stays intact. Your detection logic, your enrichments, your normalized schemas, all of it carries over.
- Add a data lake? Add a route. No re-architecture required.
- Experiment with AI-powered triage? Run platforms in parallel without doubling ingestion costs.
- Vendor plays pricing games? You have real leverage to walk away because your data layer isn't welded to their platform.
When you own your pipeline, your SIEM becomes a destination, not a dependency.
The Path Forward
SIEMs were never designed to be data pipelines, and the architecture and incentive mismatch is more obvious than ever. Vendor lock-in is getting harder to justify when budgets are tight and better options exist. AI capabilities are finally practical but demand clean data to function. The teams that own their pipeline will be the ones who actually get value from what comes next.
Let's Connect
We built Monad to give security teams that ownership. A security-native data pipeline platform with 250+ integrations, schema normalization, enrichment, and flexible routing to any destination. No vendor lock-in. No ingestion taxes. Just clean data flowing where it needs to go.
See Monad in action → Schedule a demo
Have questions about decoupling your SIEM from your data layer? Reach out to our team or explore our integration library to see how Monad connects to your stack.
Related content

.png)
