June 18, 2026
The Data Problem Every AI SOC Tool Is Counting On You to Solve First


Valerie Worman
Head of Marketing
Latio's 2026 Security Operations Market Report landed a few weeks ago, and if you read past the vendor spotlights and market maps, there's a consistent thread throughout: every meaningful SOC improvement on the horizon depends on data that is clean, well-routed, and formatted consistently. The AI SOC tools are exciting and the agentic workflows are real, but the teams that get the most out of them will be the ones that did their data homework first.
And that's not just our opinion. It's also the report's conclusion, from Latio:
"If there's one piece of practitioner advice to take from this report, it's this: start with a plan for your data architecture. Every other improvement to the SOC depends on having enriched, properly routed, and well-formatted logs. No AI analyst automation can solve underlying data problems."
We've been saying some version of this since we started building Monad. It's validating to see it written so clearly in an independent market report. More importantly, it gives us a reason to walk through the full picture — what the report found, why the data layer is the right place to start, and what the stakes look like as AI usage pushes log volumes into territory that manual approaches can't handle.
The State of the SOC in 2026
The Latio report surveyed security practitioners and leaders across industries and company sizes. Their findings are useful to level-set a lot of the vendor marketing noise right now.
On SIEM satisfaction:
- 68% of respondents are unhappy with their current SIEM
- 28% want to migrate and are actively looking
- 40% say they're unhappy but don't think the migration cost is worth it
That last number says something important about the SIEM market. A meaningful chunk feels stuck, not satisfied. They're paying for something that isn't working well, and they can't easily leave because the migration effort is brutal without the right infrastructure in place. It’s likely that this is by design rather than coincidence.
On what tools teams are actually using:
- 100% use an EDR
- 95% use a SIEM
- Only 16% use a dedicated data pipeline tool
- Only 8% run multiple SIEMs
On what SOC teams are prioritizing:
- 85% cite improving standard metrics (MTTR, MTTD)
- 63% cite AI for incident response
- 58% cite optimizing data pipelines and storage
- 40% cite bringing in asset context
The gap between the 58% of teams who say data pipeline and storage optimization is a top priority and the 16% who actually have a pipeline tool in place is the gap Monad exists to close. The market is acknowledging the problem faster than it's solving it.
Ready or Not... AI Is Here
The AI SOC conversation is moving quickly. The report finds that 80% of teams plan to keep AI development in-house rather than buying a dedicated AI SOC vendor. Of those building internally, 68% are enabling analysts to use tools like Claude Code directly in their workflows, while 32% are building custom agentic systems.
That's useful information. Most teams aren't buying a black-box AI SOC platform and hoping it figures things out; they're extending their existing analysts with AI capabilities. That's actually the more difficult path from a data quality perspective because those analysts and their AI tools need to query across whatever fragmented, inconsistently formatted data environment the team has accumulated over years.
The report is uncompromising about what happens when you skip the data work:
"Buying an AI SOC tool hoping it fixes underlying data or detection problems is how teams end up with an expensive workflow engine that hallucinates over incomplete logs — driving up costs and wasting time in the process."
Agent hallucination in a security context isn't an abstract risk. If an AI agent queries a data source and gets back incomplete or malformed results, it can either fail silently or, worse, reason confidently from bad data. The report calls this out explicitly as one of the core risks of federated search: "Agent hallucination when data does not exist, or it's unknown if it does exist."
This is why data architecture isn't an abstract prerequisite. It's a prerequisite because the thing everyone wants to build on top of it is fragile when the foundation is shaky.
Why the SIEM Wasn't Built for This
The report does a good job explaining the architectural tension at the center of the modern SOC. Traditional SIEM tools consolidate data ingestion, indexing, searching, and long-term storage into a single system. That worked reasonably well when the data environment was simpler and teams queried logs retroactively after a detection fired.
That model is increasingly misaligned with how security data actually flows now. Data is generated across cloud infrastructure, SaaS tools, identity providers, AI-native applications, and dozens of security vendors - each with their own schemas and log formats. The SIEM was never designed to be a normalization engine, a cost optimization layer, and an enrichment platform simultaneously. It was designed to store, alert, and correlate.
Latio's SIEM interoperability graph maps vendors along two axes: how open their underlying data architecture is, and how portable their detection logic is. The traditional all-in-one platforms land in the corner with vendor-specific schemas and search languages. That's not an accident; lock-in is the business model. The cost of leaving compounds every year as your detection library grows and your data accumulates in a format only one vendor can query efficiently.
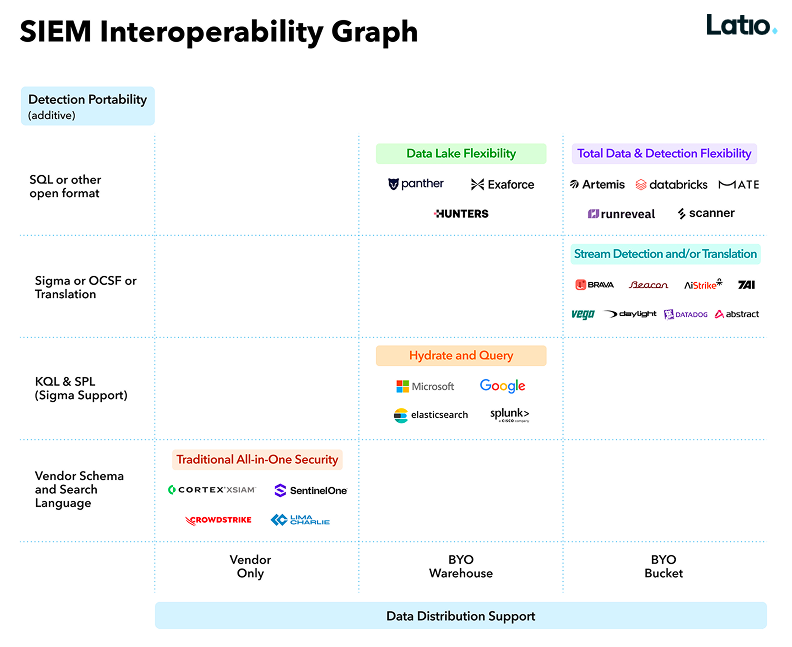
The teams moving toward more open architectures, whether that's bringing their own data lake or running detections on streaming data, are making a deliberate choice to trade some out-of-the-box simplicity for long-term flexibility. The report's framing on this supports it: "ELK is out, and data portability is in." The ELK stack (Elasticsearch, Logstash, Kibana) has been one of the SIEM backbones for the better part of a decade with ingestion, indexing, and search tightly coupled into a single system. The shift the report is describing is toward architectures built on technologies like Apache Iceberg, ClickHouse, DuckDB, and object storage where data lives in open formats that multiple tools can query.
The catch is that flexibility without structure creates its own problems. Half-completed migrations are one of the report's recurring themes:
"This has led many organizations to have multiple SIEM strategies, sometimes querying historical business data in one location, separate from their core security logs. This creates a nightmare version of the distributed SOC, where no one knows where the data lives, if it's formatted correctly, and how to access it."
A data pipeline isn't just about routing logs to new destinations. It's the thing that keeps the migration from becoming a mess that's worse than what you started with.
The Vendor Neutral Pipeline: What It Actually Does
The report divides the data pipeline market into clear categories. On one side are vendor-specific pipelines, essentially routing mechanisms that point data back into the vendor's own SIEM and other products. On the other are vendor-neutral pipelines; tools designed to work across destinations, normalize data to open schemas, and give teams control over where data goes and what it costs.
Monad is firmly in the vendor-neutral camp alongside a handful of other tools. That classification matters so much because a vendor-specific pipeline has no incentive to help you route data elsewhere or optimize costs. Their revenue is tied to your ingest volume, and they’re unlikely to do anything to compromise their revenue flow. A vendor-neutral pipeline isn’t trying to steer the customer’s other purchases, leaving them free to pick the best from each category.
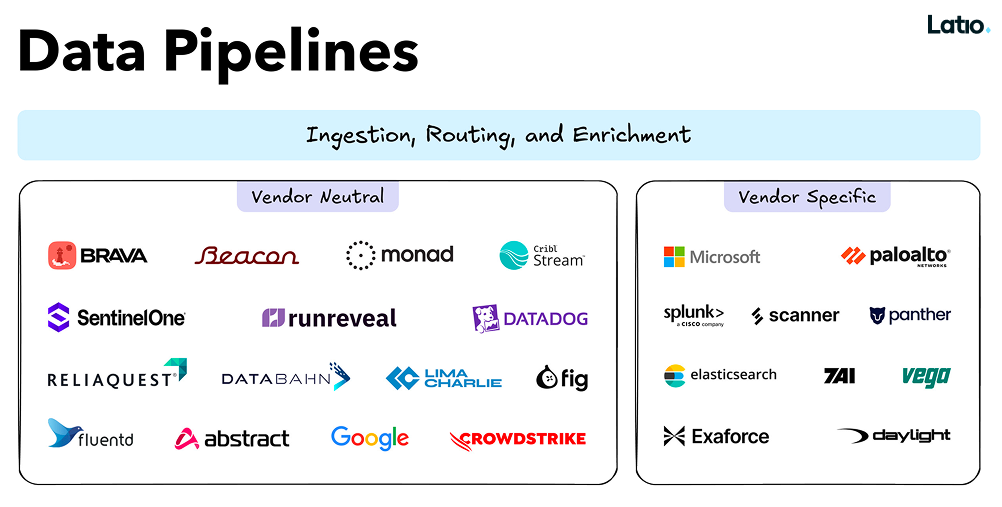
The report summarizes what good pipeline tooling actually provides:
- Normalize similar log data. Most vendors have their own log schemas for similar concepts. Data pipeline tools can standardize this into formats like OCSF or other CIM formats.
- Test for log health. Silent logging failures can lead to detections that stop firing, creating blind spots over time.
- Enrich individual logs. Adding user context, geolocation data, or asset information before a log hits the SIEM means investigators have the context they need without having to chase it down after an alert fires.
- Optimize storage costs. Route high-fidelity logs to hot storage, archive lower-priority data cheaply, drop fields that have no use, and stop paying SIEM ingestion rates for data that's never going to fire a detection.
That last point is the one that tends to get the most attention. The cost pressure from SIEM vendors is growing every day, and the math on filtering even a single noisy source can be significant. And the enrichment and normalization benefits are what matter most when AI agents enter the picture.
Why Data Volume Is the Forcing Function
Here's what the report doesn't say explicitly but that follows directly from its findings: AI usage is going to make the data problem dramatically worse before it gets better.
AI-native applications generate telemetry that most security teams haven't had to think about before. Model invocations, prompt contents, tool calls, agent decisions, API interactions with external services, etc. These are new log sources with no established schemas, highly variable outputs, and real security value that's buried inside a lot of noise.
The report touches on this in its section on AI security and telemetry: "Most teams are first focusing on protecting end-user adoption of AI, which often works on proxy-based log collection, browser plugins, or hooks." But as organizations start running their own AI agents for both business and security operations use cases, that telemetry is going to multiply.
At the same time, the AI SOC tools that teams are building in-house are going to generate their own operational logs. Every query, every investigation step, every automated response action creates a record. If those records aren't flowing into a consistent data layer, the feedback loop that makes agentic systems improve over time doesn't work.
The teams that build routing and normalization discipline now, before the AI data explosion, will be in a fundamentally different position than the teams that try to retrofit it later. The report's recommended migration sequence is worth citing here:
- Gain complete visibility into your security telemetry and where it flows through a data pipeline provider, or manual tracking. Standardizing into a format like OCSF can make the underlying data queryable.
- Consolidate your detection logic into a single authoritative location, whether a detection engineering solution or manual tracking.
- Migrate data to the new destination, preferring those that support open architectures.
The pipeline comes first. Not because it's the most exciting investment, but because everything after it depends on it being in place.
What We're Seeing at Monad
We work with security teams at companies like Robinhood, CoreWeave, and Saviynt. The pattern we see isn't that teams don't understand the data problem. Most practitioners know exactly what's wrong. The issue is that fixing it has historically required either accepting vendor lock-in or standing up a significant internal data infrastructure project.
Monad connects 300+ security sources and destinations. Teams can route data to multiple SIEMs simultaneously during a migration, normalize to OCSF without committing to it as a permanent schema, filter before data hits any storage destination, and enrich in-flight so investigators have context from the moment a log lands. Most teams are operational in days.
The reason this matters against the backdrop of the Latio report is straightforward. The tools that teams want to adopt - the AI agents, the detection engineering platforms, the modern SIEM architectures - are all downstream of data quality. If the data layer is broken, those investments under-perform. If the data layer is clean, well-routed, and consistently formatted, they work the way the vendors promise.
The report is succinct: "Every other improvement to the SOC depends on having enriched, properly routed, and well-formatted logs."
That's the work. It's not glamorous. It doesn't have an AI label on it. But it's the thing that makes everything else possible.
A Few Things to Take Away from the Report
The Latio 2026 Security Operations Market Report is worth reading in full. The vendor spotlights are detailed and fair, the market maps are genuinely useful for understanding how the category is evolving, and the survey data gives good grounding to a lot of conversations that are usually based on vibes.
A few things stood out that we think are worth holding onto as you think about your own program:
- The migration trap is serious. 40% of teams are stuck on a SIEM they don't like because leaving is too expensive. A data pipeline doesn't just reduce costs today. It's the infrastructure that makes future migrations survivable.
- Customer frustration with platforms expanding beyond security is a signal. The report notes that practitioners are frustrated with "larger platforms expanding into broader data use cases and no longer prioritizing security use cases." Single-mission vendors with no incentive to drift are a different kind of partner.
- AI without data architecture is expensive. The report identifies that AI agents need consistent, reliable access to data to reason properly. Skipping the foundation and going straight to the agent layer is a path to hallucination and cost blowout.
- 58% of teams are prioritizing data pipeline and storage optimization. That's not a niche problem - that's most of the SOC market acknowledging the same gap at the same time.
If you're working through what your data architecture should look like before your team's next AI initiative, or if you're in the middle of a SIEM evaluation and trying to figure out how to make the migration tractable, we're happy to talk through it. Schedule a demo with the Monad team.
Related content

Valerie Worman
|
July 30, 2026

.png)